exo
exo 是一款让你能在本地运行前沿大模型的开源工具,由 exo labs 维护。它的核心思路很简单:把家里或办公室里的多台设备(Mac、PC 等)连成一个人工智能计算集群,让原本单台机器跑不动的大模型也能流畅运行。
传统上,运行 671B 参数的 DeepSeek 或 235B 的 Qwen3 需要昂贵的专业 GPU 服务器。exo 解决了这个门槛问题——通过自动发现网络中的设备、智能分配计算任务,甚至利用 Thunderbolt 5 的 RDMA 技术将设备间延迟降低 99%,实现"加设备就提速"的效果。实测显示,两台设备可获得 1.8 倍加速,四台设备可达 3.2 倍。
exo 内置可视化仪表盘管理集群,并兼容 OpenAI、Claude、Ollama 等主流 API 格式,现有工具可直接接入。支持从 HuggingFace 加载自定义模型,后端基于苹果 MLX 框架优化。
这款工具特别适合 AI 研究者、开发者以及对数据隐私有要求的团队——无需将敏感数据上传云端,即可在本地体验顶尖大模型。如果你手头有多台 Mac 或混合设备,想榨干它们的联合算力,exo 是目前最成熟的解决方案之一。
使用场景
某 AI 创业公司的小团队(3 名算法工程师)正在开发一款法律文档分析产品,需要在本地测试 DeepSeek-R1 671B 大模型的推理效果,以评估是否值得采购云端 API。
没有 exo 时
- 硬件成本高昂:单台能跑 671B 模型的服务器(8×A100 80GB)售价超 20 万元,远超初创公司预算,团队只能租用云端实例,每小时成本约 50 元
- 测试流程繁琐:每次调试都需上传敏感法律合同到第三方云服务商,合规审批流程长达 2-3 天,严重拖慢迭代速度
- 资源严重闲置:工程师各自配有 M3 Max MacBook Pro(128GB 统一内存),但只能单机运行 70B 小模型,无法验证大模型在真实业务场景的表现
- 协作效率低下:三人各自独立测试,结果无法复现,模型性能数据分散在个人电脑中,团队难以形成统一评估结论
使用 exo 后
- 零额外硬件投入:通过 exo 将 3 台 MacBook Pro 自动组建成 AI 集群,利用 RDMA over Thunderbolt 技术实现设备间高速通信,总显存达 384GB,足以本地运行 671B 4-bit 量化模型
- 数据完全本地化:敏感法律文档始终留在内网环境,工程师随时启动测试,迭代周期从数天缩短至数小时
- 算力灵活调度:exo 的拓扑感知自动并行根据实时负载动态分配任务,单台设备外出办公时,其余两台自动接管,集群持续可用
- 无缝接入现有工作流:通过 OpenAI 兼容 API,直接对接团队已搭建的 LangChain 测试框架,无需修改代码即可对比不同模型的输出质量
核心价值:exo 让分散的消费级设备变身企业级 AI 算力集群,以零云成本实现大模型的本地化、隐私化、协作化开发。
运行环境要求
- macOS
- Linux
- macOS: Apple Silicon (M3 Ultra/M4 Pro/M4 Max等) 推荐,支持RDMA over Thunderbolt 5
- Linux: 目前仅CPU运行,GPU支持开发中
未说明
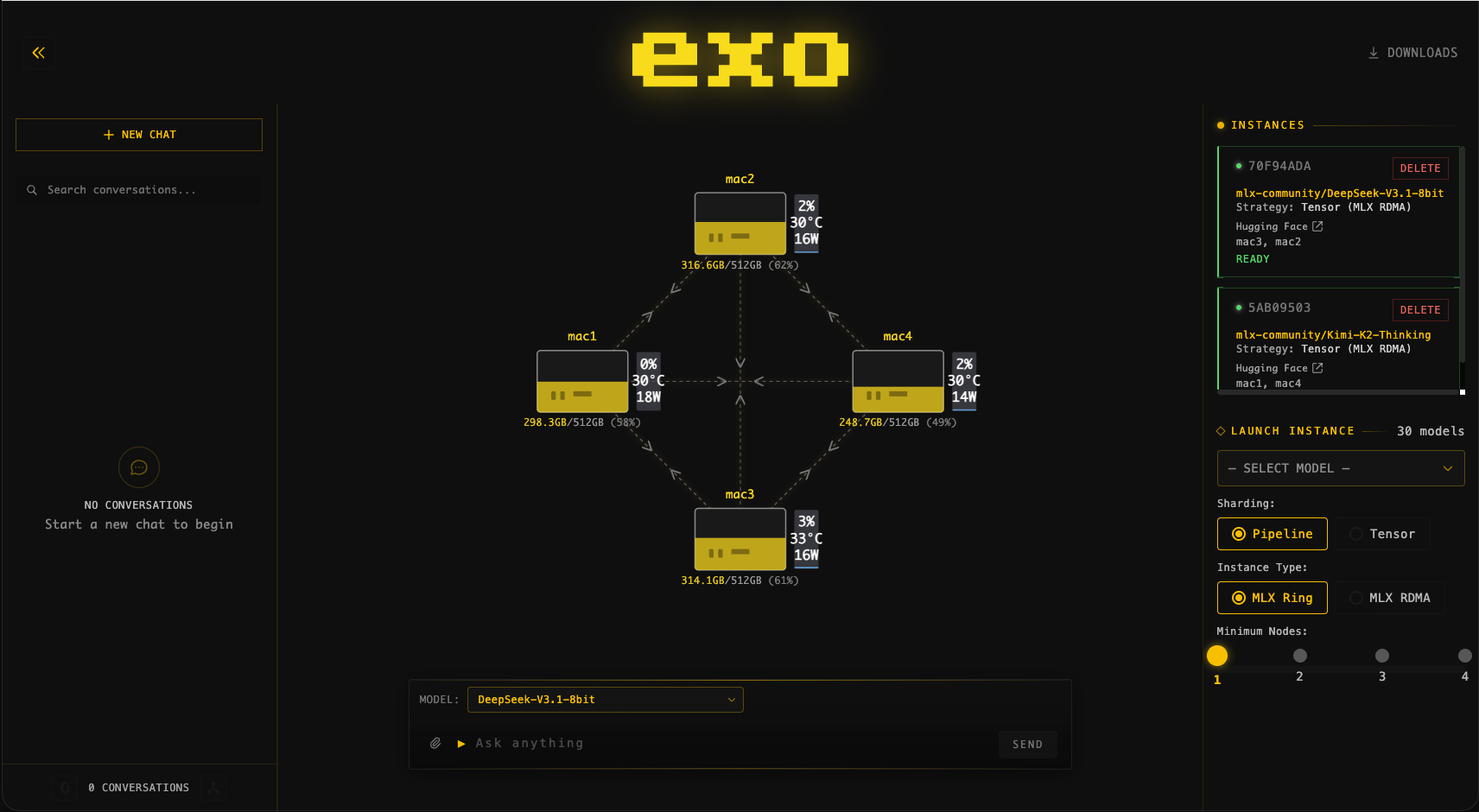
快速开始

exo 将你的所有设备连接成一个 AI 集群。exo 不仅能够运行超出单台设备容量的大型模型,而且通过 对 Thunderbolt RDMA 的 day-0 支持,让你在添加更多设备时模型运行速度更快。
功能特性
- 自动设备发现:运行 exo 的设备会自动发现彼此,无需手动配置。
- Thunderbolt RDMA:exo 内置 对 Thunderbolt 5 RDMA 的 day-0 支持,可将设备间延迟降低 99%。
- 拓扑感知自动并行:exo 会根据设备拓扑的实时视图,自动找出在所有可用设备间拆分模型的最佳方式。它会考虑设备资源以及每条链路之间的网络延迟/带宽。
- 张量并行(Tensor Parallelism):exo 支持模型分片(sharding),在 2 台设备上可获得最高 1.8 倍加速,在 4 台设备上可获得最高 3.2 倍加速。
- MLX 支持:exo 使用 MLX 作为推理后端,并使用 MLX distributed 进行分布式通信。
- 多 API 兼容:兼容 OpenAI Chat Completions API、Claude Messages API、OpenAI Responses API 和 Ollama API——可直接使用你现有的工具和客户端。
- 自定义模型支持:从 HuggingFace Hub 加载自定义模型,扩展可用模型的范围。
仪表盘
exo 包含一个内置仪表盘,用于管理集群和与模型对话。
4 × 512GB M3 Ultra Mac Studio 运行 DeepSeek v3.1(8-bit)和 Kimi-K2-Thinking(4-bit)
基准测试
Qwen3-235B(8-bit)在 4 × M3 Ultra Mac Studio 上使用张量并行 RDMA
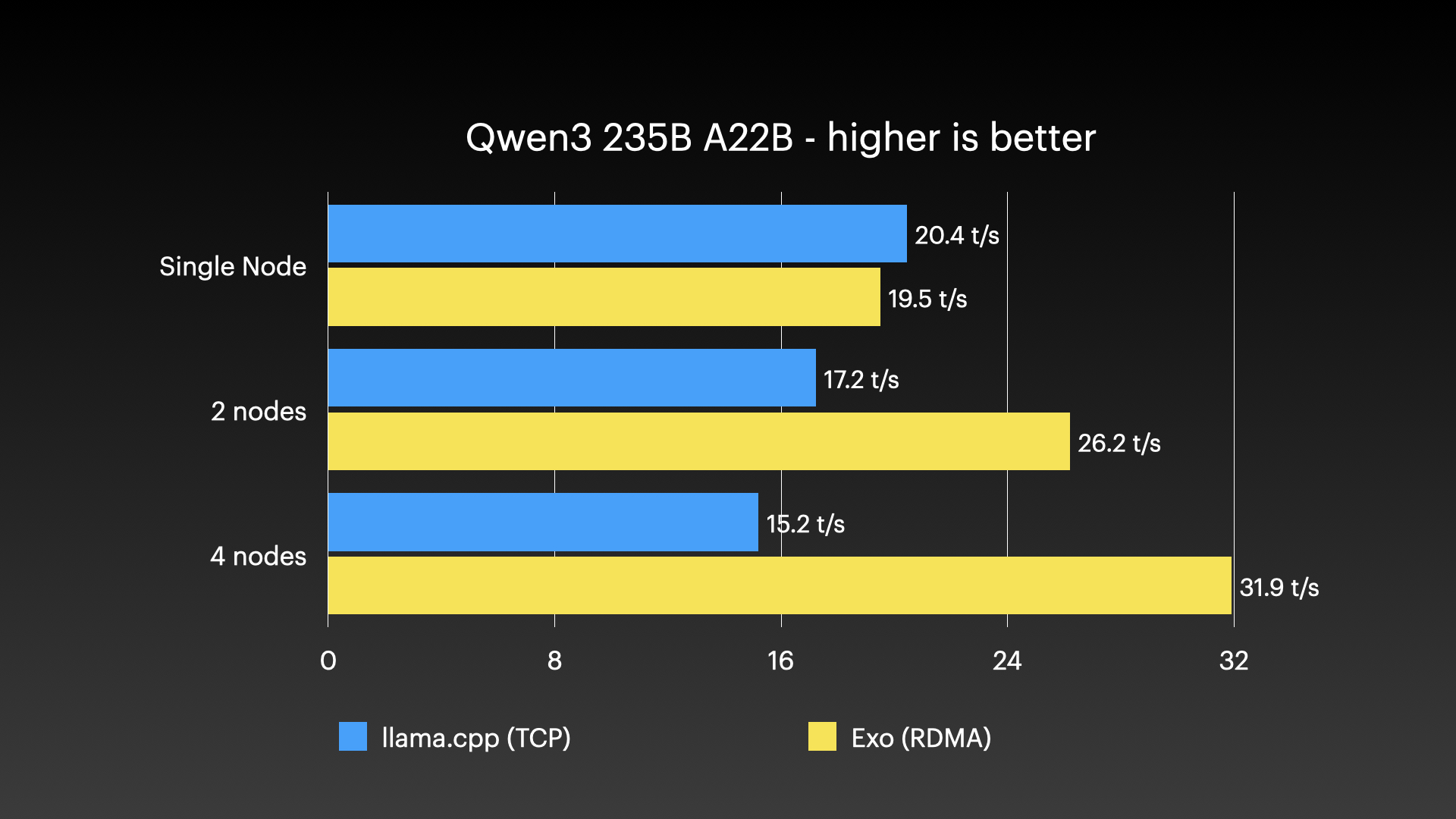
来源: Jeff Geerling:Mac Studio 上的 15 TB VRAM —— Thunderbolt 5 RDMA
DeepSeek v3.1 671B(8-bit)在 4 × M3 Ultra Mac Studio 上使用张量并行 RDMA
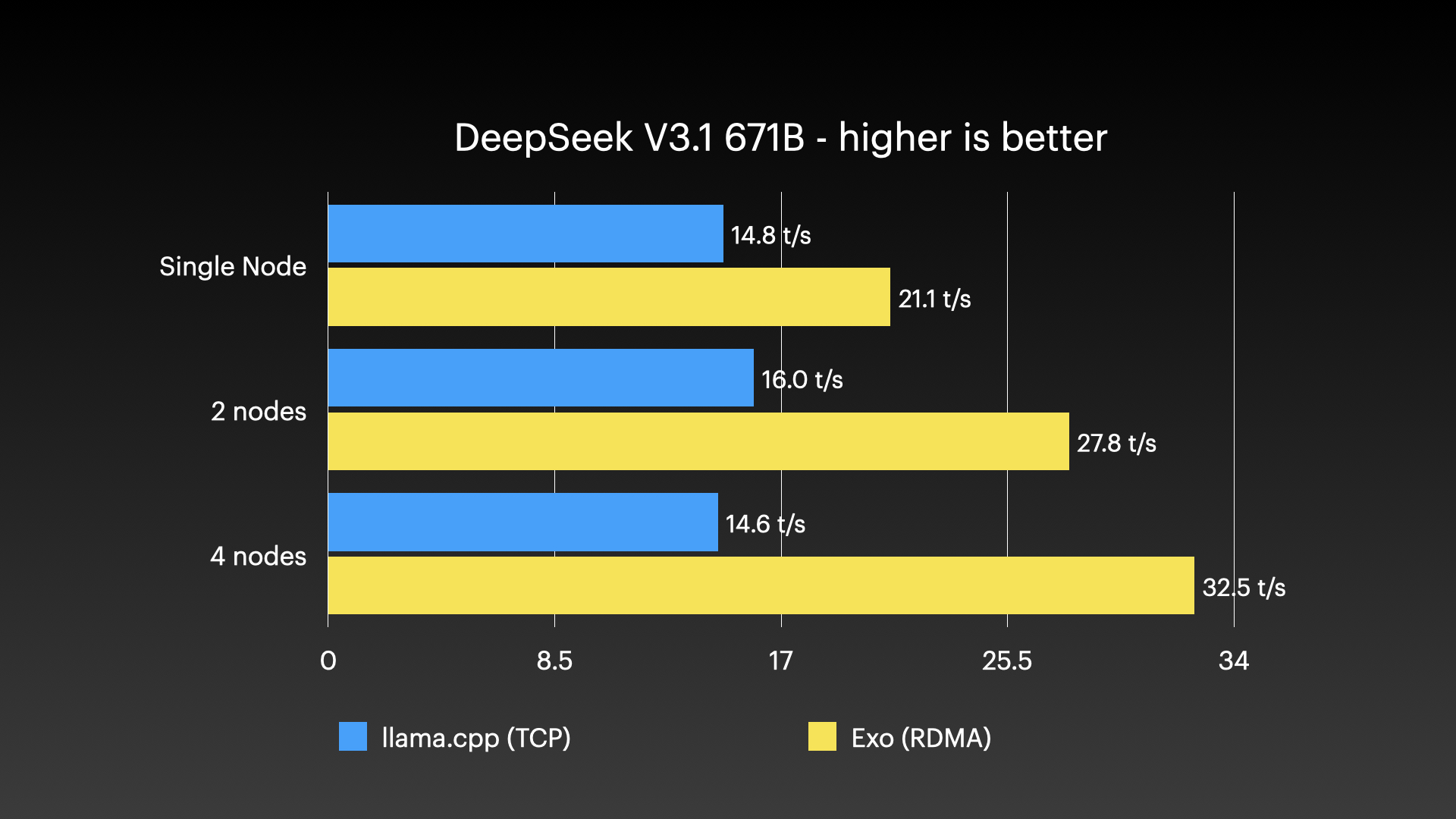
来源: Jeff Geerling:Mac Studio 上的 15 TB VRAM —— Thunderbolt 5 RDMA
Kimi K2 Thinking(原生 4-bit)在 4 × M3 Ultra Mac Studio 上使用张量并行 RDMA
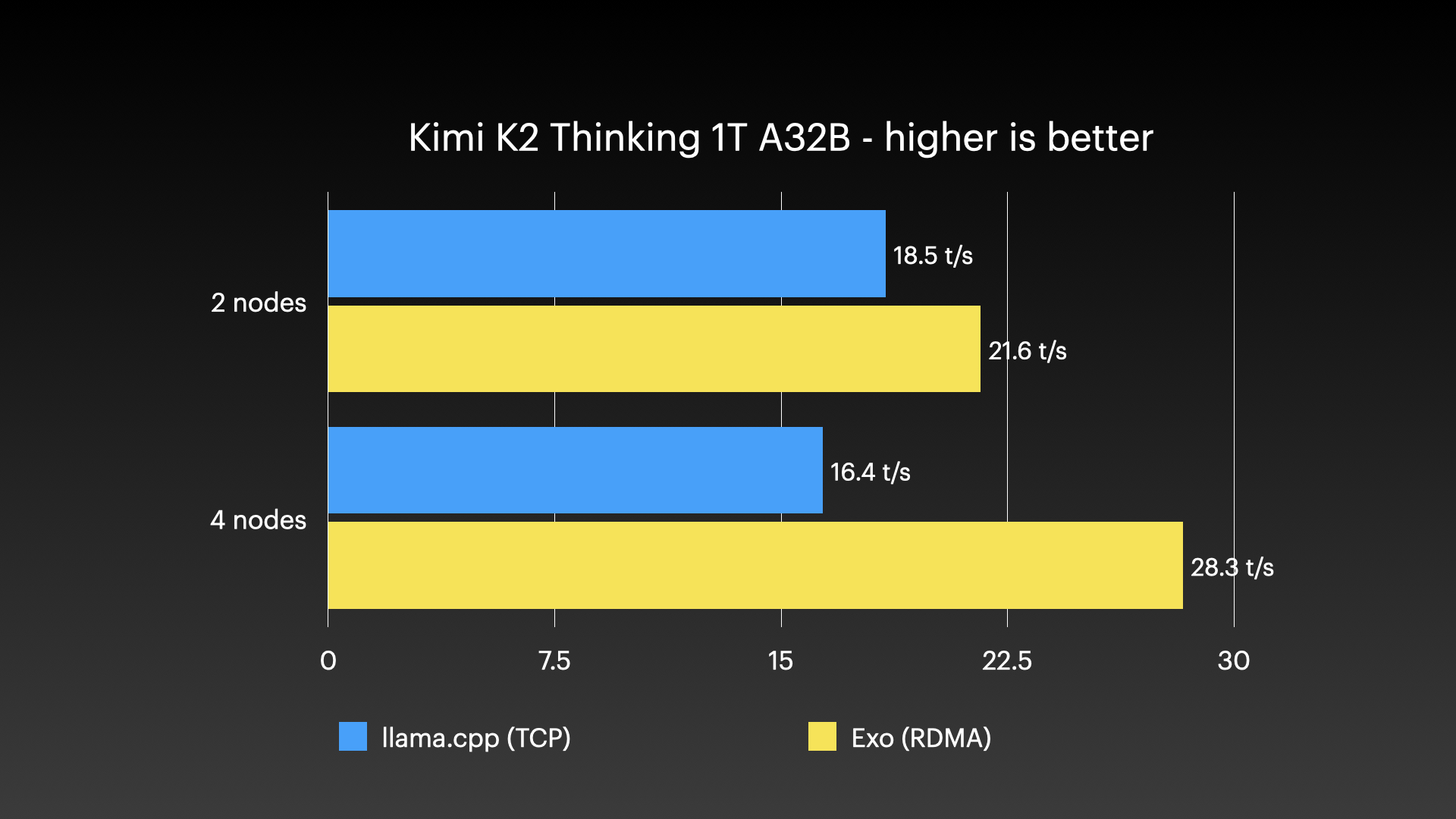
来源: Jeff Geerling:Mac Studio 上的 15 TB VRAM —— Thunderbolt 5 RDMA
快速开始
运行 exo 的设备会自动发现彼此,无需任何手动配置。每台设备都提供 API 和仪表盘用于与集群交互(运行在 http://localhost:52415)。
有两种方式运行 exo:
从源码运行(macOS)
如果你已安装 Nix,可以跳过以下大部分步骤直接运行 exo:
nix run .#exo
注意: 要接受 Cachix 二进制缓存(并避免使用 Xcode Metal ToolChain),请在 /etc/nix/nix.conf 中添加:
trusted-users = root (或你的用户名)
experimental-features = nix-command flakes
然后重启 Nix 守护进程:sudo launchctl kickstart -k system/org.nixos.nix-daemon
前置要求:
Xcode(提供 MLX 编译所需的 Metal ToolChain)
brew(用于 macOS 的简单包管理)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"uv(用于 Python 依赖管理)
node(用于构建仪表盘)
brew install uv noderust(用于构建 Rust 绑定,目前需要 nightly 版本)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh rustup toolchain install nightlymacmon(用于 Apple Silicon 的硬件监控)
请安装本仓库使用的指定 fork 版本,而非 Homebrew 的
macmon。 Homebrew 的macmon 0.6.1在 Apple M5 上仍会崩溃。cargo install --git https://github.com/swiftraccoon/macmon \ --rev 9154d234f763fbeffdcb4135d0bbbaf80609699b \ macmon \ --force
克隆仓库,构建仪表盘,然后运行 exo:
# 克隆 exo
git clone https://github.com/exo-explore/exo
# 构建仪表盘
cd exo/dashboard && npm install && npm run build && cd ..
# 运行 exo
uv run exo
这将启动 exo 仪表盘和 API,地址为 http://localhost:52415/
请查看 RDMA 相关章节,以在 macOS >=26.2 上启用此功能!
从源码运行(Linux)
前置条件:
安装方法:
选项 1:使用系统包管理器(以 Ubuntu/Debian 为例):
# 安装 Node.js 和 npm
sudo apt update
sudo apt install nodejs npm
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装 Rust(使用 rustup)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup toolchain install nightly
选项 2:在 Linux 上使用 Homebrew(如偏好此方式):
# 在 Linux 上安装 Homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装依赖
brew install uv node
# 安装 Rust(使用 rustup)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
rustup toolchain install nightly
注意: macmon 包仅适用于 macOS,Linux 上不需要。
克隆仓库,构建仪表盘,然后运行 exo:
# 克隆 exo
git clone https://github.com/exo-explore/exo
# 构建仪表盘
cd exo/dashboard && npm install && npm run build && cd ..
# 运行 exo
uv run exo
这会在 http://localhost:52415/ 启动 exo 仪表盘和 API。
Linux 用户重要提示: 目前,exo 在 Linux 上仅使用 CPU 运行。Linux 平台的 GPU 支持正在开发中。如果您希望看到对特定 Linux 硬件的支持,请搜索现有的功能请求或创建新的功能请求。
配置选项:
--no-worker:在不运行 worker 组件的情况下启动 exo。适用于仅作为协调器(coordinator)的节点,这类节点负责网络和编排,但不执行推理任务。对于 GPU 资源不足但网络连接良好的机器很有帮助。uv run exo --no-worker
文件位置(Linux):
exo 在 Linux 上遵循 XDG 基础目录规范:
- 配置文件:
~/.config/exo/(或$XDG_CONFIG_HOME/exo/) - 数据文件:
~/.local/share/exo/(或$XDG_DATA_HOME/exo/) - 缓存文件:
~/.cache/exo/(或$XDG_CACHE_HOME/exo/) - 日志文件:
~/.cache/exo/exo_log/(自动日志轮转) - 自定义模型卡片:
~/.local/share/exo/custom_model_cards/
您可以通过设置相应的 XDG 环境变量来覆盖这些位置。
macOS 应用
exo 提供了一个 macOS 应用,可在您的 Mac 后台运行。
macOS 应用需要 macOS Tahoe 26.2 或更高版本。
在此下载最新版本:EXO-latest.dmg。
应用会请求修改系统设置和安装新网络配置文件的权限。相关改进正在进行中。
用于集群隔离的自定义命名空间:
macOS 应用包含自定义命名空间功能,允许您将 exo 集群与同一网络上的其他集群隔离。此功能通过 EXO_LIBP2P_NAMESPACE 设置进行配置:
使用场景:
- 在同一网络上运行多个独立的 exo 集群
- 将开发/测试集群与生产集群隔离
- 防止意外加入集群
配置:在应用的高级设置中访问此设置(或在从源码运行时设置
EXO_LIBP2P_NAMESPACE环境变量)
命名空间会在启动时记录,用于调试目的。
卸载 macOS 应用
推荐的卸载方式是通过应用本身:点击菜单栏图标 → 高级 → 卸载。这会干净地移除所有系统组件。
如果您已经删除了应用,可以运行独立的卸载脚本:
sudo ./app/EXO/uninstall-exo.sh
这会移除:
- 网络设置的 LaunchDaemon
- 网络配置脚本
- 日志文件
- "exo" 网络位置
注意: 您需要手动从系统设置 → 通用 → 登录项中移除 EXO。
在 macOS 上启用 RDMA
RDMA(远程直接内存访问,Remote Direct Memory Access)是 macOS 26.2 新增的功能。它适用于任何配备 Thunderbolt 5 的 Mac(M4 Pro Mac Mini、M4 Max Mac Studio、M4 Max MacBook Pro、M3 Ultra Mac Studio)。
请参阅注意事项以进行即时故障排除。
要在 macOS 上启用 RDMA,请按以下步骤操作:
- 关闭 Mac。
- 按住电源按钮 10 秒,直到出现启动菜单。
- 选择"选项"进入恢复模式。
- 当恢复界面出现时,从实用工具菜单打开终端。
- 在终端中输入:
然后按回车键。rdma_ctl enable - 重新启动 Mac。
之后,RDMA 将在 macOS 中启用,exo 会自动处理其余配置。
重要注意事项
- 希望加入 RDMA 集群的设备必须与集群中的所有其他设备连接。
- 线缆必须支持 TB5。
- 在 Mac Studio 上,不能使用以太网端口旁边的 Thunderbolt 5 端口。
- 如果从源码运行,请使用
tmp/set_rdma_network_config.sh脚本,该脚本会禁用 Thunderbolt Bridge 并在每个 RDMA 端口上设置 DHCP。 - RDMA 端口可能无法在不同版本的 macOS 上相互发现。请确保所有设备的操作系统版本完全匹配(包括 beta 版本号)。
环境变量
exo 支持多个用于配置的环境变量:
| 变量 | 描述 | 默认值 |
|---|---|---|
EXO_DEFAULT_MODELS_DIR |
模型下载和缓存的默认目录。始终位于可写目录列表的首位。 | ~/.local/share/exo/models(Linux)或 ~/.exo/models(macOS) |
EXO_MODELS_DIRS |
以冒号分隔的额外可写目录,用于模型下载。按顺序在默认目录之后检查;使用第一个有足够可用空间的目录。 | 无 |
EXO_MODELS_READ_ONLY_DIRS |
以冒号分隔的只读目录,用于搜索预下载的模型(例如 NFS 挂载、共享存储)。此处的模型无法删除。 | 无 |
EXO_OFFLINE |
在无网络连接的情况下运行(仅使用本地模型) | false |
EXO_ENABLE_IMAGE_MODELS |
启用图像模型支持 | false |
EXO_LIBP2P_NAMESPACE |
用于集群隔离的自定义命名空间 | 无 |
EXO_FAST_SYNCH |
控制 MLX_METAL_FAST_SYNCH 行为(用于 JACCL 后端) | 自动 |
EXO_TRACING_ENABLED |
启用分布式追踪以进行性能分析 | false |
使用示例:
# 从 NFS 挂载使用预下载的模型(只读)
EXO_MODELS_READ_ONLY_DIRS=/mnt/nfs/models:/opt/ai-models uv run exo
# 将模型下载到外部 SSD(如果已满则回退到默认目录)
EXO_MODELS_DIRS=/Volumes/ExternalSSD/exo-models uv run exo
# 离线模式运行
EXO_OFFLINE=true uv run exo
# 启用图像模型
EXO_ENABLE_IMAGE_MODELS=true uv run exo
# 使用自定义命名空间进行集群隔离
EXO_LIBP2P_NAMESPACE=my-dev-cluster uv run exo
使用 API
exo 提供多种 API 兼容接口,以最大程度兼容现有工具:
- OpenAI Chat Completions API - 兼容 OpenAI 客户端
- Claude Messages API - 兼容 Anthropic 的 Claude 格式
- OpenAI Responses API - 兼容 OpenAI 的 Responses 格式
- Ollama API - 兼容 Ollama 及 OpenWebUI 等工具
如果你希望通过 API 与 exo 交互,以下示例展示了如何创建一个小型模型实例(mlx-community/Llama-3.2-1B-Instruct-4bit)、发送聊天补全请求以及删除实例。
1. 预览实例部署方案
/instance/previews 端点会预览模型的所有有效部署方案。
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b"
示例响应:
{
"previews": [
{
"model_id": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"sharding": "Pipeline",
"instance_meta": "MlxRing",
"instance": {...},
"memory_delta_by_node": {"local": 729808896},
"error": null
}
// ...可能有更多部署方案...
]
}
这将返回该模型的所有有效部署方案。选择你喜欢的方案。
要选择第一个,使用 jq 管道:
curl "http://localhost:52415/instance/previews?model_id=llama-3.2-1b" | jq -c '.previews[] | select(.error == null) | .instance' | head -n1
2. 创建模型实例
向 /instance 发送 POST 请求,在 instance 字段中指定你想要的部署方案(完整负载必须与 CreateInstanceParams 中的类型匹配),可从第 1 步复制:
curl -X POST http://localhost:52415/instance \
-H 'Content-Type: application/json' \
-d '{
"instance": {...}
}'
示例响应:
{
"message": "Command received.",
"command_id": "e9d1a8ab-...."
}
3. 发送聊天补全请求
现在,向 /v1/chat/completions 发送 POST 请求(与 OpenAI API 格式相同):
curl -N -X POST http://localhost:52415/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages": [
{"role": "user", "content": "What is Llama 3.2 1B?"}
],
"stream": true
}'
4. 删除实例
完成后,通过实例 ID 删除实例(可通过 /state 或 /instance 端点查找):
curl -X DELETE http://localhost:52415/instance/YOUR_INSTANCE_ID
Claude Messages API 兼容性
使用 /v1/messages 端点,采用 Claude Messages API 格式:
curl -N -X POST http://localhost:52415/v1/messages \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages": [
{"role": "user", "content": "Hello"}
],
"max_tokens": 1024,
"stream": true
}'
OpenAI Responses API 兼容性
使用 /v1/responses 端点,采用 OpenAI Responses API 格式:
curl -N -X POST http://localhost:52415/v1/responses \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages": [
{"role": "user", "content": "Hello"}
],
"stream": true
}'
Ollama API 兼容性
exo 支持 Ollama API 端点,以兼容 OpenWebUI 等工具:
# Ollama 聊天
curl -X POST http://localhost:52415/ollama/api/chat \
-H 'Content-Type: application/json' \
-d '{
"model": "mlx-community/Llama-3.2-1B-Instruct-4bit",
"messages": [
{"role": "user", "content": "Hello"}
],
"stream": false
}'
# 列出模型(Ollama 格式)
curl http://localhost:52415/ollama/api/tags
从 HuggingFace 加载自定义模型
你可以从 HuggingFace Hub 添加自定义模型:
curl -X POST http://localhost:52415/models/add \
-H 'Content-Type: application/json' \
-d '{
"model_id": "mlx-community/my-custom-model"
}'
安全提示:
配置中需要 trust_remote_code 的自定义模型必须显式启用(默认为 false)以确保安全。仅在信任模型远程代码执行的情况下启用此选项。模型从 HuggingFace 获取并作为自定义模型卡片本地存储。
其他有用的 API 端点:
- 列出所有模型:
curl http://localhost:52415/models - 仅列出已下载模型:
curl http://localhost:52415/models?status=downloaded - 搜索 HuggingFace:
curl "http://localhost:52415/models/search?query=llama&limit=10" - 查看实例 ID 和部署状态:
curl http://localhost:52415/state
更多详情,请参阅:
- docs/api.md 中的 API 文档
- src/exo/master/api.py 中的 API 类型和端点
基准测试
exo-bench 工具用于测量不同部署配置下的模型预填充(prefill)和 Token 生成速度。这有助于优化模型性能并验证改进效果。
前置条件:
- 基准测试前节点应已运行
uv run exo - 该工具使用
/bench/chat/completions端点
基本用法:
uv run bench/exo_bench.py \
--model Llama-3.2-1B-Instruct-4bit \
--pp 128,256,512 \
--tg 128,256
关键参数:
--model:要基准测试的模型(短 ID 或 HuggingFace ID)--pp:提示词大小提示(逗号分隔的整数)--tg:生成长度(逗号分隔的整数)--max-nodes:将部署方案限制为 N 个节点(默认:4)--instance-meta:按ring、jaccl或both过滤(默认:both)--sharding:按pipeline、tensor或both过滤(默认:both)--repeat:每种配置的重复次数(默认:1)--warmup:每种部署方案的预热运行次数(默认:0)--json-out:结果输出文件(默认:bench/results.json)
带过滤的示例:
uv run bench/exo_bench.py \
--model Llama-3.2-1B-Instruct-4bit \
--pp 128,512 \
--tg 128 \
--max-nodes 2 \
--sharding tensor \
--repeat 3 \
--json-out my-results.json
该工具输出性能指标,包括每种配置的每秒提示词 Token 数(prompt_tps)、每秒生成 Token 数(generation_tps)和峰值内存使用量。
硬件加速器支持
在 macOS 上,exo 使用 GPU。在 Linux 上,exo 目前运行在 CPU 上。我们正在努力扩展硬件加速器支持。如果你希望支持新的硬件平台,请搜索现有功能请求并点赞,以便我们了解社区重视的硬件。
贡献
请参阅 CONTRIBUTING.md 了解如何为 exo 做出贡献的指南。
版本历史
v1.0.692026/03/27v1.0.682026/02/25v1.0.672026/01/28v1.0.662026/01/26v1.0.652026/01/24v1.0.642026/01/23v1.0.632026/01/16v1.0.622026/01/08v1.0.612026/01/08v1.0.61-alpha.22026/01/08v1.0.61-alpha.12026/01/06v1.0.61-alpha.02026/01/05v1.0.60-alpha02025/12/22v1.0.60-alpha.12025/12/22常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。