nanochat
nanochat 是一个专为大型语言模型(LLM)训练设计的极简实验框架。它的核心目标是让 LLM 训练变得触手可及,覆盖了从分词、预训练、微调到评估、推理及聊天 UI 的全流程。nanochat 显著降低了训练成本与复杂度,曾经需要 4.3 万美元才能训练的 GPT-2 级别模型,现在仅需约 48 美元(使用 8xH100 GPU 运行 2 小时)即可完成,并支持在网页界面中直接对话。
nanochat 非常适合开发者、研究人员以及希望深入理解 LLM 构建原理的技术爱好者。代码精简且易于修改,只需单 GPU 节点即可运行。其独特亮点在于“一键式”超参数优化:用户只需调整模型层数(--depth),其余如模型宽度、学习率等参数均会自动计算为最优配置。此外,nanochat 还建立了训练速度排行榜,鼓励社区协作不断突破效率极限。通过 uv 管理依赖,上手便捷,是探索大模型训练技术的理想起点。无论是用于教学演示还是快速验证新想法,nanochat 都能提供高效且透明的支持。
使用场景
某高校 AI 实验室希望让学生完整体验大模型训练流程,从数据预处理到聊天界面部署,但面临预算有限且缺乏大规模集群运维经验的困境。
没有 nanochat 时
- 成本高昂:复现 GPT-2 级别模型在 2019 年需约 43,000 美元,远超普通课题经费预算。
- 配置复杂:需手动调整层数、学习率、权重衰减等大量超参数,调优门槛极高。
- 流程割裂:训练、评估、推理往往需拼接不同代码库,难以一站式完成实验。
- 硬件依赖:通常需要多节点集群支持,单卡难以运行完整训练流程。
使用 nanochat 后
- 成本极低:nanochat 仅需约 48 美元(2 小时 8xH100)即可训练出同等能力模型,预算降低三个数量级。
- 自动调优:只需设定
--depth参数,nanochat 自动计算最优超参数组合,无需人工干预。 - 全流程整合:nanochat 涵盖分词到聊天 UI 的所有阶段,代码极简且易于修改 hack。
- 单节点运行:nanochat 优化为单 GPU 节点运行,无需复杂集群配置即可启动训练。
nanochat 将大模型训练从“烧钱实验”变为“人人可及的开发体验”,极大降低了研究与学习门槛。
运行环境要求
- Linux
- macOS
- 非必需但推荐
- 训练推荐 NVIDIA A100/H100 (80GB 显存)
- 支持单卡或多卡 (8x)
- 显存小于 80GB 需调整 --device-batch-size
- 支持 CPU/MPS 但需缩小模型
未说明

快速开始
nanochat
nanochat 是用于训练大型语言模型(LLMs)的最简单的实验框架。它设计为在单个图形处理器(GPU)节点上运行,代码极简/可修改,涵盖了所有主要的 LLM 阶段,包括分词(tokenization)、预训练(pretraining)、微调(finetuning)、评估(evaluation)、推理(inference)以及聊天用户界面(UI)。例如,你只需花费 48 美元(8XH100 GPU 节点约 2 小时)即可训练出自己的具备 GPT-2 能力的 LLM(2019 年训练成本约为 43,000 美元),然后通过熟悉的类 ChatGPT Web UI 与之对话。如果使用竞价实例(spot instance),总成本可接近 15 美元左右。更一般地说,nanochat 开箱即用配置为训练整个计算最优模型迷你系列,只需设置一个复杂度调节器:--depth,即 GPT Transformer 模型中的层数(GPT-2 能力大约对应深度 26)。所有其他超参数(hyperparameters)(Transformer 宽度、头数、学习率调整、训练周期、权重衰减等)都会以最优方式自动计算。
关于仓库的问题,我建议要么使用 Devin/Cognition 的 DeepWiki 来询问关于仓库的问题,要么使用 Discussions 标签页,或者加入 Discord 上的 #nanochat 频道。
达到 GPT-2 水平耗时排行榜
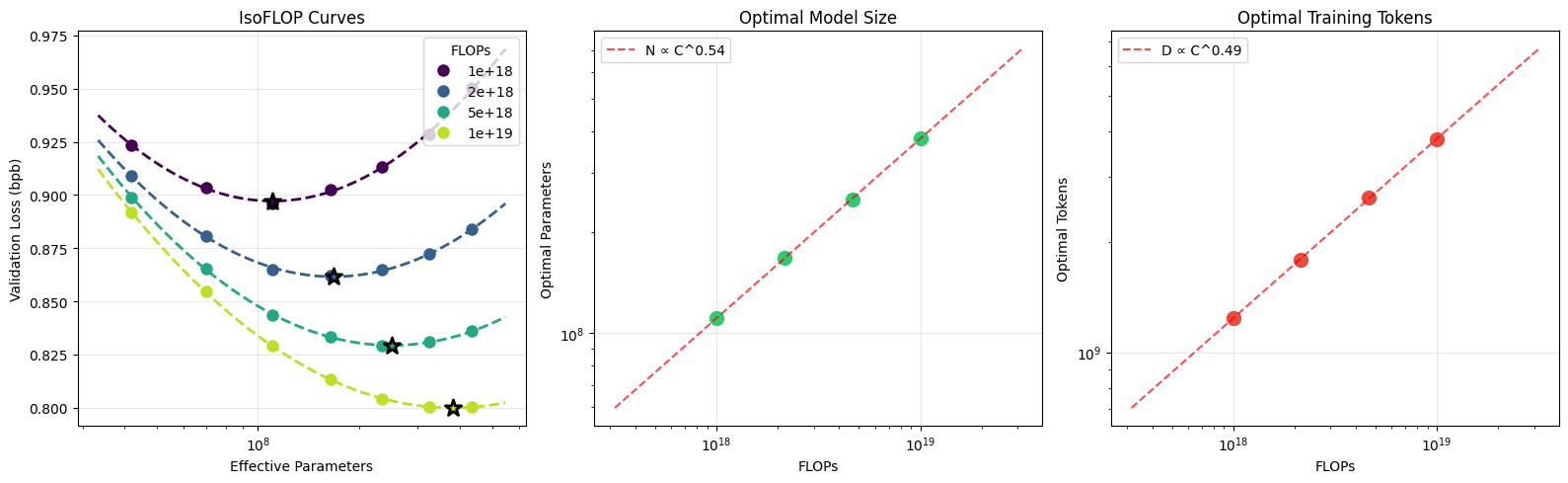
目前,开发的主要重点是调整预训练(pretraining)阶段,这是计算量最大的部分。受 modded-nanogpt 仓库启发,为了激励进步和社区协作,nanochat 维护了一个"GPT-2 速通”排行榜,即根据 DCLM CORE 分数衡量,训练 nanochat 模型达到 GPT-2 等级能力所需的挂钟时间(wall-clock time)。runs/speedrun.sh 脚本始终反映了训练 GPT-2 等级模型并与之对话的参考方法。当前排行榜如下:
| # | 时间 | val_bpb | CORE | 描述 | 日期 | 提交 | 贡献者 |
|---|---|---|---|---|---|---|---|
| 0 | 168 小时 | - | 0.2565 | 原始 OpenAI GPT-2 检查点(checkpoint) | 2019 | - | OpenAI |
| 1 | 3.04 | 0.74833 | 0.2585 | d24 基线,略微过训练 | 2026 年 1 月 29 日 | 348fbb3 | @karpathy |
| 2 | 2.91 | 0.74504 | 0.2578 | d26 略微欠训练 +fp8 | 2026 年 2 月 2 日 | a67eba3 | @karpathy |
| 3 | 2.76 | 0.74645 | 0.2602 | 将总批次大小(batch size)提升至 1M tokens | 2026 年 2 月 5 日 | 2c062aa | @karpathy |
| 4 | 2.02 | 0.71854 | 0.2571 | 更换数据集为 NVIDIA ClimbMix | 2026 年 3 月 4 日 | 324e69c | @ddudek @karpathy |
| 5 | 1.80 | 0.71808 | 0.2690 | 自动研究(autoresearch)第 1 轮 | 2026 年 3 月 9 日 | 6ed7d1d | @karpathy |
| 6 | 1.65 | 0.71800 | 0.2626 | 自动研究第 2 轮 | 2026 年 3 月 14 日 | a825e63 | @karpathy |
我们关心的主要指标是“达到 GPT-2 水平耗时”——即在 8XH100 GPU 节点上超越 GPT-2 (1.6B) CORE 指标所需的挂钟时间。GPT-2 CORE 分数为 0.256525。2019 年,训练 GPT-2 的成本约为 43,000 美元,因此令人难以置信的是,由于 7 年来整个技术栈的许多进步,我们现在可以做得更快,且成本远低于 100 美元(例如,按当前 ~$3/GPU/小时计算,8XH100 节点约为 24 美元/小时,所以 2 小时约为 48 美元)。
请参阅 dev/LEADERBOARD.md 获取更多关于如何解读和贡献排行榜的文档。
快速开始
设置
nanochat 使用 uv 进行依赖管理。安装方法:
uv sync --extra gpu # Use for CUDA (A100/H100/etc.)
uv sync --extra cpu # (or) Use for CPU-only / MPS
source .venv/bin/activate
用于开发(添加 pytest, matplotlib, ipykernel, transformers 等):
uv sync --extra gpu --group dev
复现并与 GPT-2 对话
最有趣的事情莫过于训练你自己的 GPT-2 并与之对话。实现这一目标的整个流程都包含在单个文件 runs/speedrun.sh 中,该文件设计用于在 8XH100 GPU 节点上运行。从你喜欢的提供商启动一个新的 8XH100 GPU 机器(例如,我使用并喜欢 Lambda),然后启动训练脚本:
bash runs/speedrun.sh
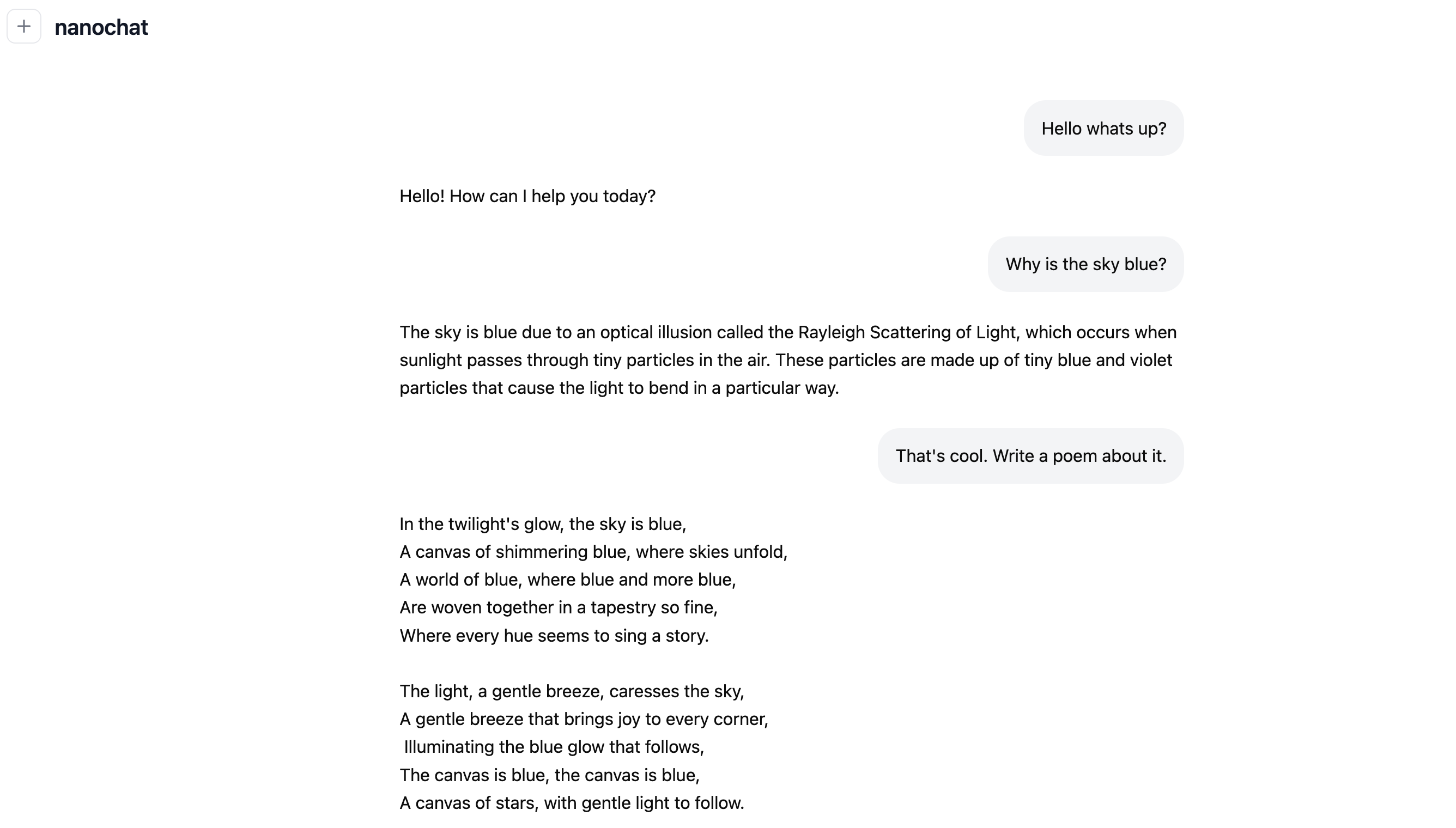
你可能希望在 screen 会话中执行此操作,因为运行需要约 3 小时。完成后,你可以通过类 ChatGPT Web UI 与之对话。再次确保你的本地 uv 虚拟环境(virtual environment)已激活(运行 source .venv/bin/activate),然后启动服务:
python -m scripts.chat_web
然后访问显示的 URL。确保正确访问,例如在 Lambda 上使用你所在节点的公网 IP,后跟端口,例如 http://209.20.xxx.xxx:8000/ 等。然后像平常使用 ChatGPT 一样与你的 LLM 对话!让它写故事或诗歌。让它告诉你是谁,看看幻觉(hallucination)。问它天空为什么是蓝色的。或者为什么是绿色的。速跑模型是一个 4e19 浮点运算次数(FLOPs)能力的模型,所以有点像在与幼儿园小朋友对话 :).
更多说明:
- 代码也可以在 Ampere 8XA100 GPU 节点上正常运行,但会稍慢一些。
- 所有代码即使在单个 GPU 上也能正常运行,只需省略
torchrun,并将产生几乎相同的结果(代码会自动切换到梯度累积(gradient accumulation)),但你必须等待 8 倍长的时间。 - 如果你的 GPU 显存(VRAM)小于 80GB,你将不得不调整一些超参数,否则会遇到内存溢出(OOM)/ 显存不足。在脚本中查找
--device-batch-size并减小它直到适配。例如从 32(默认)减到 16, 8, 4, 2,甚至 1。低于这个值,你就需要更清楚自己在做什么并更具创造性。 - 大部分代码是相当标准的 PyTorch,因此它应该能在任何支持该框架的设备上运行 - xpu, mps 等,但我没有亲自测试过所有这些代码路径,所以可能存在一些问题。
研究
如果您是研究人员并希望帮助改进 nanochat,两个感兴趣的脚本是 runs/scaling_laws.sh 和 runs/miniseries.sh。参见 Jan 7 miniseries v1 获取相关文档。对于快速实验(约 5 分钟的 pretraining (预训练) 运行),我最喜欢的规模是训练一个 12 层模型(GPT-1 大小),例如这样:
OMP_NUM_THREADS=1 torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- \
--depth=12 \
--run="d12" \
--model-tag="d12" \
--core-metric-every=999999 \
--sample-every=-1 \
--save-every=-1 \
这使用了 wandb (实验跟踪工具)(运行名称 "d12"),仅在最后一步运行 CORE 指标,并且不采样和保存中间 checkpoints (检查点)。我喜欢更改代码中的某些内容,重新运行 d12(或 d16 等),看看是否有帮助,形成一个迭代循环。为了查看运行是否有帮助,我喜欢监控 wandb 图表中的以下内容:
val_bpb(validation loss (验证损失),单位为每字节比特数 bits per byte,与词汇表大小无关),作为step、total_training_time和total_training_flops的函数。core_metric(DCLM CORE 分数)- VRAM 利用率,
train/mfu(Model FLOPS 利用率),train/tok_per_sec(training throughput (训练吞吐量))
参见此处的示例 here。
需要注意的重要一点是,nanochat 是围绕单一复杂度旋钮编写和配置的——Transformer (Transformer 架构) 的 depth (深度)。这个单一整数自动确定所有其他 hyperparameters (超参数)(Transformer 的 width (宽度)、number of heads (头数)、learning rate (学习率) 调整、training horizons (训练 horizon)、weight decays (权重衰减)、...),以便训练出的模型是 compute optimal (计算最优) 的。理念是用户无需思考或设置任何内容,他们只需使用 --depth 请求更小或更大的模型,一切就会“自动正常工作”。通过扫描 depth (深度),您可以在各种尺寸下实现 nanochat compute optimal (计算最优) 模型的 miniseries (迷你系列)。GPT-2 能力模型(目前最感兴趣的)恰好位于当前代码的 d24-d26 范围内。但是,对仓库的任何候选更改都必须足够有原则,以便它们适用于所有 depth (深度) 设置。
在 CPU / MPS 上运行
脚本 runs/runcpu.sh 展示了一个在 CPU 或 Apple Silicon 上运行的非常简单的示例。它极大地缩小了正在训练的 LLM (大型语言模型),以适应几十分钟的合理训练时间间隔。通过这种方式您不会获得强大的结果。
精度 / dtype
nanochat 不使用 torch.amp.autocast。相反,精度通过单个全局 COMPUTE_DTYPE(定义在 nanochat/common.py 中)显式管理。默认情况下,这是根据您的硬件自动检测的:
| Hardware | Default dtype | Why |
|---|---|---|
| CUDA SM 80+ (A100, H100, ...) | bfloat16 |
原生 bf16 tensor cores (张量核心) |
| CUDA SM < 80 (V100, T4, ...) | float32 |
无 bf16;可通过 NANOCHAT_DTYPE=float16 使用 fp16(使用 GradScaler) |
| CPU / MPS | float32 |
无低精度 tensor cores (张量核心) |
您可以使用 NANOCHAT_DTYPE 环境变量覆盖默认值:
NANOCHAT_DTYPE=float32 python -m scripts.chat_cli -p "hello" # force fp32
NANOCHAT_DTYPE=bfloat16 torchrun --nproc_per_node=8 -m scripts.base_train # force bf16
工作原理:模型权重存储在 fp32 中(用于 optimizer (优化器) 精度),但我们的自定义 Linear (线性) 层在 forward pass (前向传播) 期间将它们转换为 COMPUTE_DTYPE。Embeddings (嵌入层) 直接存储在 COMPUTE_DTYPE 中以节省内存。这给了我们与 autocast 相同的 mixed-precision (混合精度) 优势,但可以完全显式控制哪些部分以何种精度运行。
注意:float16 训练会自动在 base_train.py 中启用 GradScaler 以防止 gradient underflow (梯度下溢)。SFT (监督微调) 也支持这一点,但 RL (强化学习) 目前不支持。Inference (推理) 在 fp16 下在任何地方都能正常工作。
指南
我发布了许多可能包含有用信息的指南,按从最近到最远排序:
- 2026 年 2 月 1 日:以 <<$100 的成本超越 GPT-2:nanochat 之旅
- 1 月 7 日 miniseries v1 记录了第一个 nanochat 模型 miniseries (迷你系列)。
- 要为 nanochat 添加新功能,请参阅 指南:计算 strawberry 中的 r(以及如何普遍添加功能)。
- 要自定义您的 nanochat,请参阅 Discussions 中的 指南:为您的 nanochat 注入身份,其中描述了如何通过合成数据生成并将该数据混合到 SFT (监督微调) 阶段来调整 nanochat 的个性。
- 2025 年 10 月 13 日:原始 nanochat 帖子 介绍了 nanochat,虽然现在包含一些已弃用的信息,且模型比当前 master 分支旧得多(结果更差)。
文件结构
.
├── LICENSE
├── README.md
├── dev
│ ├── gen_synthetic_data.py # Example synthetic data for identity
│ ├── generate_logo.html
│ ├── nanochat.png
│ └── repackage_data_reference.py # Pretraining data shard generation
├── nanochat
│ ├── __init__.py # empty
│ ├── checkpoint_manager.py # Save/Load model checkpoints
│ ├── common.py # Misc small utilities, quality of life
│ ├── core_eval.py # Evaluates base model CORE score (DCLM paper)
│ ├── dataloader.py # Tokenizing Distributed Data Loader
│ ├── dataset.py # Download/read utils for pretraining data
│ ├── engine.py # Efficient model inference with KV Cache
│ ├── execution.py # Allows the LLM to execute Python code as tool
│ ├── gpt.py # The GPT nn.Module Transformer
│ ├── logo.svg
│ ├── loss_eval.py # Evaluate bits per byte (instead of loss)
│ ├── optim.py # AdamW + Muon optimizer, 1GPU and distributed
│ ├── report.py # Utilities for writing the nanochat Report
│ ├── tokenizer.py # BPE Tokenizer wrapper in style of GPT-4
│ └── ui.html # HTML/CSS/JS for nanochat frontend
├── pyproject.toml
├── runs
│ ├── miniseries.sh # Miniseries training script
│ ├── runcpu.sh # Small example of how to run on CPU/MPS
│ ├── scaling_laws.sh # Scaling laws experiments
│ └── speedrun.sh # Train the ~$100 nanochat d20
├── scripts
│ ├── base_eval.py # Base model: CORE score, bits per byte, samples
│ ├── base_train.py # Base model: train
│ ├── chat_cli.py # Chat model: talk to over CLI
│ ├── chat_eval.py # Chat model: eval tasks
│ ├── chat_rl.py # Chat model: reinforcement learning
│ ├── chat_sft.py # Chat model: train SFT
│ ├── chat_web.py # Chat model: talk to over WebUI
│ ├── tok_eval.py # Tokenizer: evaluate compression rate
│ └── tok_train.py # Tokenizer: train it
├── tasks
│ ├── arc.py # Multiple choice science questions
│ ├── common.py # TaskMixture | TaskSequence
│ ├── customjson.py # Make Task from arbitrary jsonl convos
│ ├── gsm8k.py # 8K Grade School Math questions
│ ├── humaneval.py # Misnomer; Simple Python coding task
│ ├── mmlu.py # Multiple choice questions, broad topics
│ ├── smoltalk.py # Conglomerate dataset of SmolTalk from HF
│ └── spellingbee.py # Task teaching model to spell/count letters
├── tests
│ └── test_engine.py
└── uv.lock
贡献
nanochat 的目标是改进 micro models (微型模型) 的最先进水平,使其能够在低于 1000 美元的预算下实现 end to end (端到端) 工作。易用性 (Accessibility) 不仅关乎总体成本,也关乎 cognitive complexity (认知复杂度) —— nanochat 不是一个可详尽配置的 LLM (大型语言模型) “框架”;代码库 (code base) 中没有巨大的配置对象 (configuration objects)、模型工厂 (model factories) 或复杂的条件判断逻辑 (if-then-else monsters)。它是一个单一、连贯、极简、可读、可修改、最大可分叉的“强基线 (strong baseline)"代码库,旨在从头到尾运行,并产生一个你可以对话的 ChatGPT 模型。目前,个人最感兴趣的部分是加速达到 GPT-2 水平的延迟 (latency)(即获得高于 0.256525 的 CORE score (CORE 分数))。目前这需要约 3 小时,但通过改进 pretraining (预训练) 阶段,我们可以进一步提升。
当前 AI 政策:披露 (disclosure)。当提交 PR (合并请求) 时,请声明任何有 LLM (大型语言模型) 实质贡献的部分,以及任何非你撰写或你未完全理解的部分。
致谢
- 名称 (nanochat) 源于我早期的项目 nanoGPT,该项目仅涵盖 pretraining (预训练)。
- nanochat 也受到 modded-nanoGPT 的启发,该项目通过清晰的指标和 leaderboard (排行榜) 将 nanoGPT 仓库游戏化,并借用了其许多想法和部分 pretraining (预训练) 实现。
- 感谢 HuggingFace 提供 fineweb 和 smoltalk。
- 感谢 Lambda 提供开发本项目所用的 compute (算力)。
- 感谢首席 LLM (大型语言模型) 调教专家 🧙♂️ Alec Radford 提供的建议/指导。
- 感谢仓库主管 (repo czar) Sofie @svlandeg 帮助管理 nanochat 的问题、pull requests (合并请求) 和讨论。
引用
如果您发现 nanochat 对您的研究有帮助,请按以下方式引用:
@misc{nanochat,
author = {Andrej Karpathy},
title = {nanochat: The best ChatGPT that \$100 can buy},
year = {2025},
publisher = {GitHub},
url = {https://github.com/karpathy/nanochat}
}
许可证
MIT
常见问题
相似工具推荐
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
ragflow
RAGFlow 是一款领先的开源检索增强生成(RAG)引擎,旨在为大语言模型构建更精准、可靠的上下文层。它巧妙地将前沿的 RAG 技术与智能体(Agent)能力相结合,不仅支持从各类文档中高效提取知识,还能让模型基于这些知识进行逻辑推理和任务执行。 在大模型应用中,幻觉问题和知识滞后是常见痛点。RAGFlow 通过深度解析复杂文档结构(如表格、图表及混合排版),显著提升了信息检索的准确度,从而有效减少模型“胡编乱造”的现象,确保回答既有据可依又具备时效性。其内置的智能体机制更进一步,使系统不仅能回答问题,还能自主规划步骤解决复杂问题。 这款工具特别适合开发者、企业技术团队以及 AI 研究人员使用。无论是希望快速搭建私有知识库问答系统,还是致力于探索大模型在垂直领域落地的创新者,都能从中受益。RAGFlow 提供了可视化的工作流编排界面和灵活的 API 接口,既降低了非算法背景用户的上手门槛,也满足了专业开发者对系统深度定制的需求。作为基于 Apache 2.0 协议开源的项目,它正成为连接通用大模型与行业专有知识之间的重要桥梁。